This week I’ve been working on extracting records from a service and enhancing
them with extra data. The api of this service supports a fairly typical paging
style of ?page=x&limit=y; which allowed me to form parallel requests to fully
saturate ingesting and processing of the data. At the start of task things
looked great with my measurements, it was processing about 1200 records a
second! Several minutes in the rate began to plummet to ~250 a second. What
was going on?
Pictured below is a Kibana graph I made looking at the service I was pulling from. Every request is accounted for with the Y axis being how many requests happened in that time and the X axis being at what time. Using a little more filtering I also segmented the request times into two groups. Every request that took less then a second is green and every request over a second is yellow.
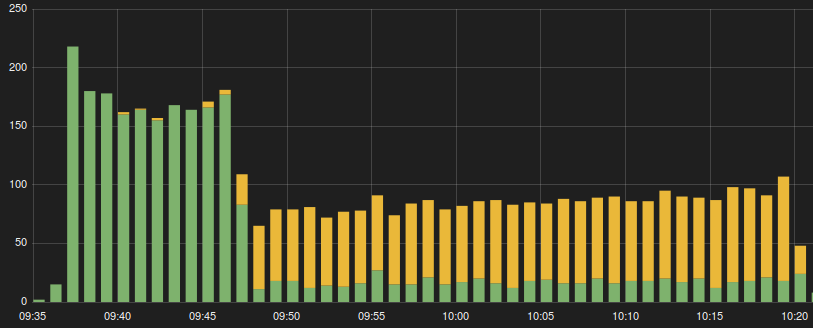
Here we can see that the service starts to slow down and never recovers. After looking through logs I found that the database was getting slower. Once I started digging into the service I found that the offset used to page the data was killing query performance.
First, let’s look at the query being performed with an explain.
|
|
So far this isn’t bad with an index scan on the primary key index. This shows why the start against the api went well. Now, let’s see what happens when we simulate a request further into the data.
|
|
If you see Seq Scan on table_name you are guaranteed to be heading down a
trail of pain. What this means is a sort is happening against the table without
utilizing any kind of index. What’s worse, is under the hood Postgres is
building up a list of 5020 rows, only to grab the last 20. You can imagine how
this will get worse and worse the further back in the pages you go.
Luckily there are ways to avoid this. If for instance if your id’s are set to auto-increment you could accomplish the same result as above with much better results:
|
|
A caveat to this strategy, it assumes there are no gaps in your records. If there are deleted rows it would not equal the same value as the offset option. For what I was trying to accomplish it turns out if that is the case it really doesn’t matter so long as the records are downloaded and processed. With that in mind I switched to this and saw BIG performance gains.
This won’t work for everything of course, and would need to be tailored to how
you want to see data in your application. For instance, lets say you want to
always show 25 records per page and order them by updated_at. Probably the
best thing to do in that case would be to be to do something like:
|
By selecting 50 records we can show 25 and now have enough data to support going
ahead to the next page or page 3. For instance, if the last record of our
result set looked like updated_at=103947728, id=83944 and the 25th record was
updated_at=103948728, id=89331 we could fetch these respective pages like so:
|
EDIT (2015-10-19) Thanks to Robert Ulejczyk for pointing out to use row value queries above and also mentioning that you may want to have a two-column index on the above columns for performance.
This doesn’t support jumping to arbitrary pages and does involve fetching more records at a time then we need to; however, it helps avoid using offset.
I’m not saying to rip out all of your paging code now. In fact for most end user scenarios using offset is probably fine, especially when the user has oodles of filter and sorting options at their disposal. Chances are they won’t go back too many pages to where it matters. If however you are generating a lengthy report or large sections of your data is being operating on in a programmatic manner you may want to worry about this. It was eating up performance time for me and could be for you as well.
TL;DR If the chance of paging through your entire data set is 100% you shouldn’t use offset for paging through the records.